Project Statement
The tech industry is dominated by the ‘California Ideology’, a belief “that the government [and] state bureaucracies are a challenge to individual freedom and economic growth”, it includes Ayn Rand-ism, civil libertarianism, and the notion of a ‘techno-elite’ (Week 7 Lecture 5:10). This ideology has led to the pursuit of technological progress and profits without concern for how these technologies might harm others. In “Tech, Heal Thyself”, Ellen Pao notes how tech companies were once pitched with noble goals such as Google’s goal to “Organize the world's information and make it universally accessible and useful”, but over time venture capital started funding companies focused on replacing people with technology. When you believe that profit is an inherent moral good, it’s easy to toss away concerns about how your technology is or could harm people.
This ‘California Ideology’ was witnessed first-hand when a famous venture capital firm, Y Combinator, recently visited UW-Madison. They brought with them the founders of a company who is creating an AI Recruiter specifically for “under $30/hour” jobs. During the talk the founders of the company played a demo of their product. We listened to an awkward call where a lifeless AI voice repeatedly asked someone if they had 15 minutes to talk about the role. Later, during a question-and-answer section, someone asked them if it was ethical to have AI call people without them knowing. They responded with a non-answer about how their system was better than an “overworked recruiter” completely ignoring the question at hand. One of the Y Combinator employees chimed in and effectively said that if you aren’t one of the people building these technologies, you don’t get a say in if they are or aren’t ethical. This encounter highlights the fact that AI systems are being developed by people indifferent to ethical concerns.
As tech companies bulldoze forward with AI technologies, it is important now more than ever to understand how these technologies harm people. Buolawmini started her book “Unmasking AI” with the anecdote of how off-the-shelf facial recognition technology couldn’t recognize her face but could if she was wearing a white mask (pg 9-10). This was an example of the ‘coded-gaze’ a term she coined to describe “the ways in which the priorities, preferences, and prejudices of those who have the power to shape technology can propagate harm” (pg 10). Because the creators of these facial recognition tools didn’t have dark skin, they failed to consider people with dark skin in the testing and evaluation of their facial recognition too, leading to it performing noticeably worse on people with dark skin.
Buolawmini couldn’t get off-the-shelf facial tracking technology to recognize her face, until she wore a white mask. The AI models used in these facial tracking software packages reflected the biases of the people that created them. Because the creators of these AI models were not testing them on black women and other minority groups, they were less effective at detecting their faces. When IBM became aware their model was misidentifying black women, they created an updated model that was better able to detect their faces increasing accuracy from 65.3% to 96.5%.
However, in order to truly understand the coded-gaze, it must be analyzed through the lens of intersectionality. It is not enough to analyze how the coded-gaze affects people along one axis (race, gender, etc.), only by analyzing “many axes that work together and influence each other” can the coded-gaze be truly understood (Patricia Hill Collins & Sirma Bilge 2016 via Week 1 Lecture). An example of this is IBM’s Face++, while their facial recognition AI performed well on dark males (99.3% accuracy) and light skinned females (98.3% accuracy), it performed terribly on dark skinned females (65.3% accuracy) (Buolamwini 141). Simply analyzing along one axis would have missed this glaring equality: the AI performed well on people with dark skin and the AI performed well on women, but it didn’t perform well on dark skinned women. When IBM designed a new model with intersectionality in mind, they were able to improve the performance on darker females from 65.3% to 96.5% accuracy (Buolamwini 151).
This lesson that defaults are not neutral from 'Unmasking AI' resonates with us, and as we create our own artificial intelligence systems, we want to try to be cognizant of the fact that biases in our training data will be reflected in our AI model. By training on and testing with many different kinds of pets, we reduce the risk of a pet getting misclassified by our model. While we will likely be unable to completely eliminate bias or error from our model, by ensuring we have diverse training and testing data, we reduce the amount of bias present in our model.
Historical examples like the LDK camera, with settings for skin-tone variation, show that “alternative systems can be made” (Buolamwini 60). AI systems have the potential to reinforce existing biases, as evidenced by Amazon’s failed hiring AI that when trained on existing hiring data, discriminated against women because “there are very, very few women working in powerful tech jobs at Amazon” (Kantayya 0:27:00-0:27:44). When designing our AI model we included many different kinds of pets, not just traditional pets such as cats and dogs. By including these pets, we increase the chance our model is able to recognize a less common pet, and therefore we are less likely to reinforce any ideas of what a ‘normal’ pet is. We are unlikely to be able to truly represent all pets, but by creating as large of a dataset as we can we reduce this bias.
The inability to ever truly eliminate bias from our model emphasizes the importance of one of the boldest lessons from ”Unmasking AI”: sometimes technologies are simply not worth creating or using. In a White House roundtable with then-president Joe Biden, Buolamwini urged Biden to “stop the use of facial recognition by the TSA for domestic flights specifically, but also its use for mass surveillance more broadly” (pg 286). AI tools can be extremely harmful for use cases such as policing and law enforcement. In situations where the harms of potential bias are too high or developers fail to remove bias from a tool, it is better to simply not create it than to make the world a worse place.
With this in mind we wanted to create a tool with low potential to cause harm, ultimately choosing to make a tool for identifying pets. The correctness of a pet classification can be verified by the user of our tool after it makes a guess by researching more about the animal our tool thinks the pet is. If our tool makes an incorrect guess, after researching the animal, the user is ultimately just left where they started. The focus on classifying pets instead of people also lets us ensure that our tool can be equally used by all sorts of different people, since the model doesn’t directly depend on the person using the tool. We attempted to collect a large dataset representing many different pets, and feel our model is low enough risk to release as a demo on our website.
Training the Model
When we started training the model, we began with Cheddar. He’s got a unique fluffy look, so it felt like a good first test case. After that we added Lulu, who has a similar energy, but shorter hair and slightly different posture.
Then we added Jamey, who has similar coloring to Lulu, which helped the model get better at noticing more detailed features. To differentiate our classes, we added Jasper, since he’s not a cat and has a very different appearance. That way, we could mix pet types and see how well the model handled variation.
Our first iteration allowed users to identify only the provided pets, so for our final iteration we modified our classifications to classify not just specific pets but instead generally identify their pets. At first it was really hard to find free images for a lot of different pets such as guinea pigs, so we reduced our classes to specifically: Cats, Dogs, Bunnies, Fish, Snakes, and Birds.
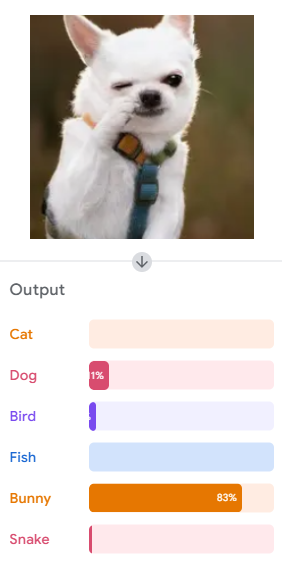
We quickly found a lot of limitations with our classifier. For instance, small white dogs and cats are often mistaken for bunnies. As well, fluffy dogs can be mistake as cats. We tried to combat the fluffy dog issue by adding samples of Corey who has some fluff to him. This helped in a lot of cases but there are still some gaps. Finally, we couldn’t find many samples of fish and snakes so the classifer runs into a lot of issues when it comes to classifying fish and snakes. Still the classifer has gotten some very clear detailed images correct.
Video Demo
In this demo we go through all the pets types: Cat, Dog, Bunny, Fish, Bird, and Snake.
The video is just a demonstration of how the machine works under the hood
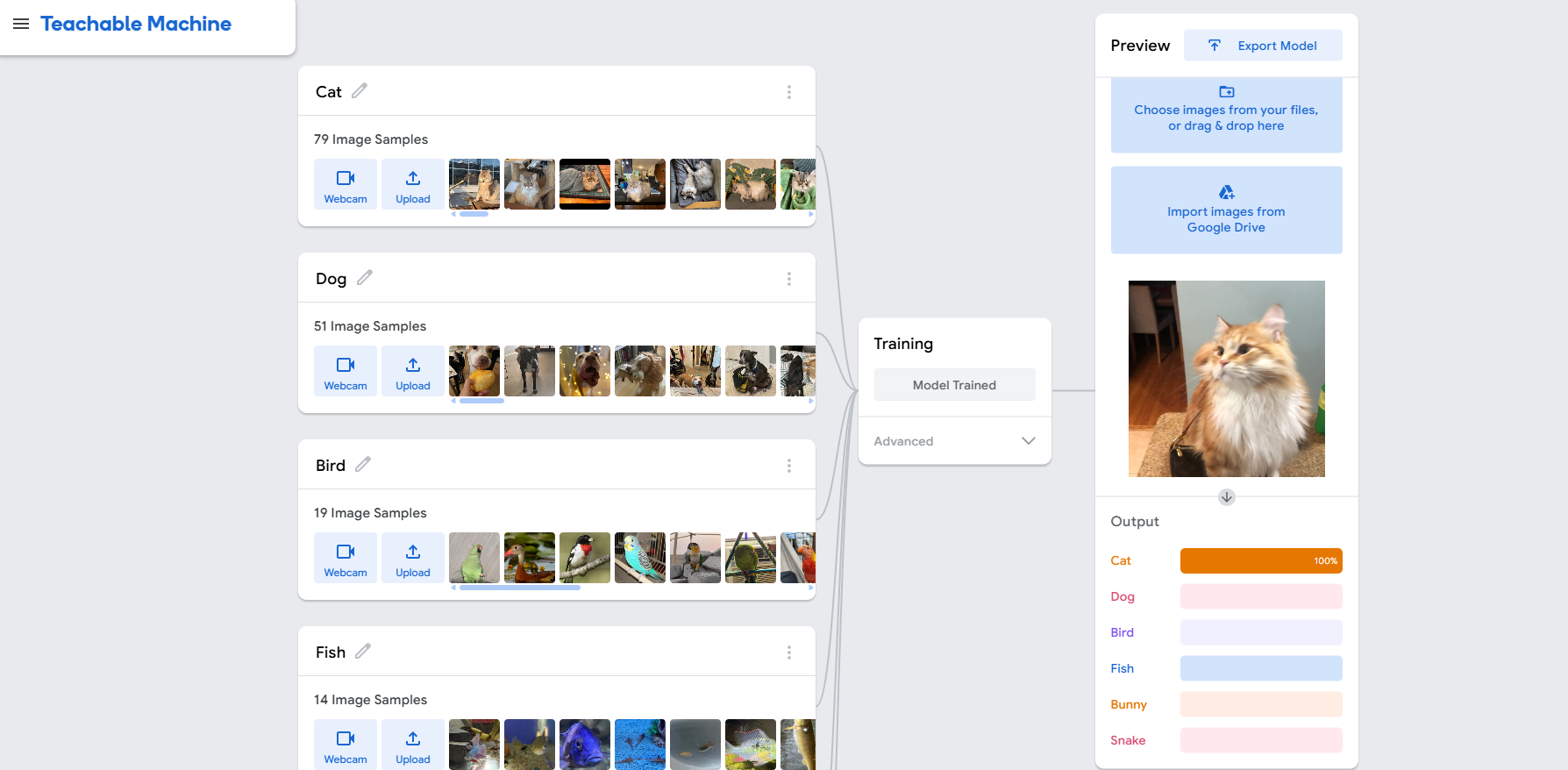
Try It Out!
How It Works
This tool uses a machine learning model trained in Google's Teachable Machine. We've used ml5.js and p5.js to integrate that model into a web page, allowing you to classify images of pets by dragging them into a central drop zone.
The model has been trained on specific photos of our pets— Jasper, Cheddar, Jamey, Corey, Charlie, Bunners, Kilamanjaro, Paisley, Selena, Toaster, Lemon, Coy, Lulu, and a few more friends. Try dropping one in to see if the classifier gets it right!
If you want to test our classifier yourself, you can upload your own image with the "Choose File" option, or you can switch to camera mode and show your pet to the camera! Just make sure to switch back to upload mode if you want to go back to uploading your own images or dropping in one of our pets.
Prediction: ...
Personal Reflections
Human Made Art is Vital - Tristan
This project made me think a lot about where AI fits into everything. Not just tech, but art, identity, even the stuff we believe about progress. The idea that tech is neutral felt kind of ridiculous by the end of all this. AI just copies what already exists, including all the bias, and puts it into something that looks shiny and new. Like facial recognition failing Black and Brown women or hiring tools that reflect old patterns instead of breaking them. It’s not some mistake, it’s the system working exactly how it was trained to.
On the creative side, I’ve always loved art because it feels personal. Whether it’s manga, street art, or something weird in a museum, there’s a human behind it. AI can’t do that. It can remix and copy and even trick people sometimes, but it can’t feel. It doesn’t understand context or pain or joy. It just predicts what should come next. That’s not creativity. That’s code. I don’t want a world where the things that move us are made without feeling.
AI art "is an insult to life itself" - Hayao Miyazaki the co-founder, director, and creative visionary behind Studio Ghibli.
Biased Data, Same Problems - Ben
What stood out to me most was how artificial intelligence depends entirely on the past. Every system we looked at was just repeating old data in new forms. And when that data is biased, the system becomes biased. It’s not just about who builds the tech, it’s also about the information we feed into it. Amazon’s AI didn’t hate women. It was just trained on hiring data that already did. That’s the problem.
I also kept coming back to the question of moral imagination. Can a machine ever have it? Right now, AI reacts to patterns, but it doesn’t understand them. It can use language or visuals that trigger an emotion, but it’s not the same as creating something from experience. That difference matters. Especially when AI is being used in things like policing, hiring, or even making art. It’s easy to get caught up in the hype. But we need to slow down and ask who this tech is serving, and at what cost.